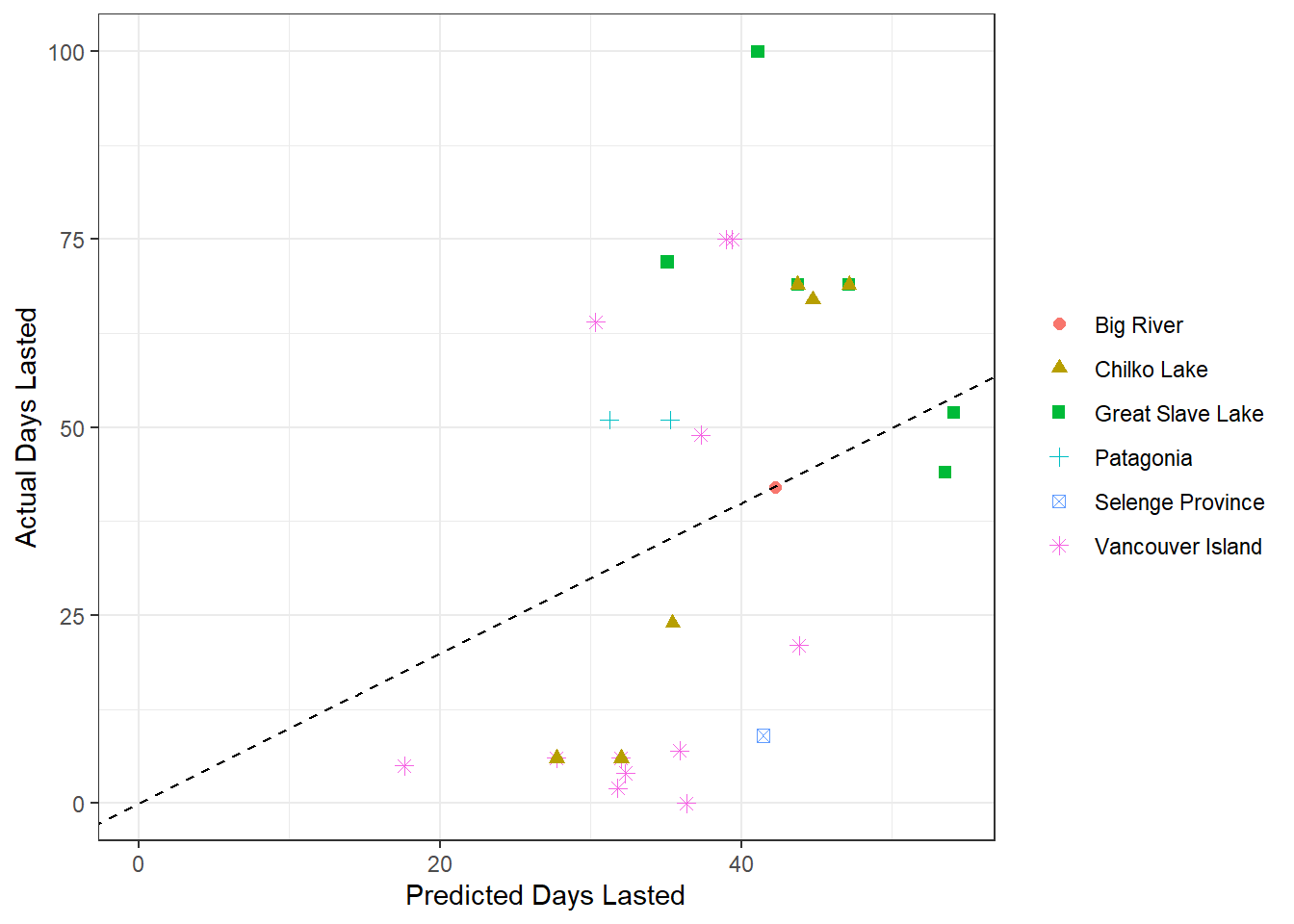
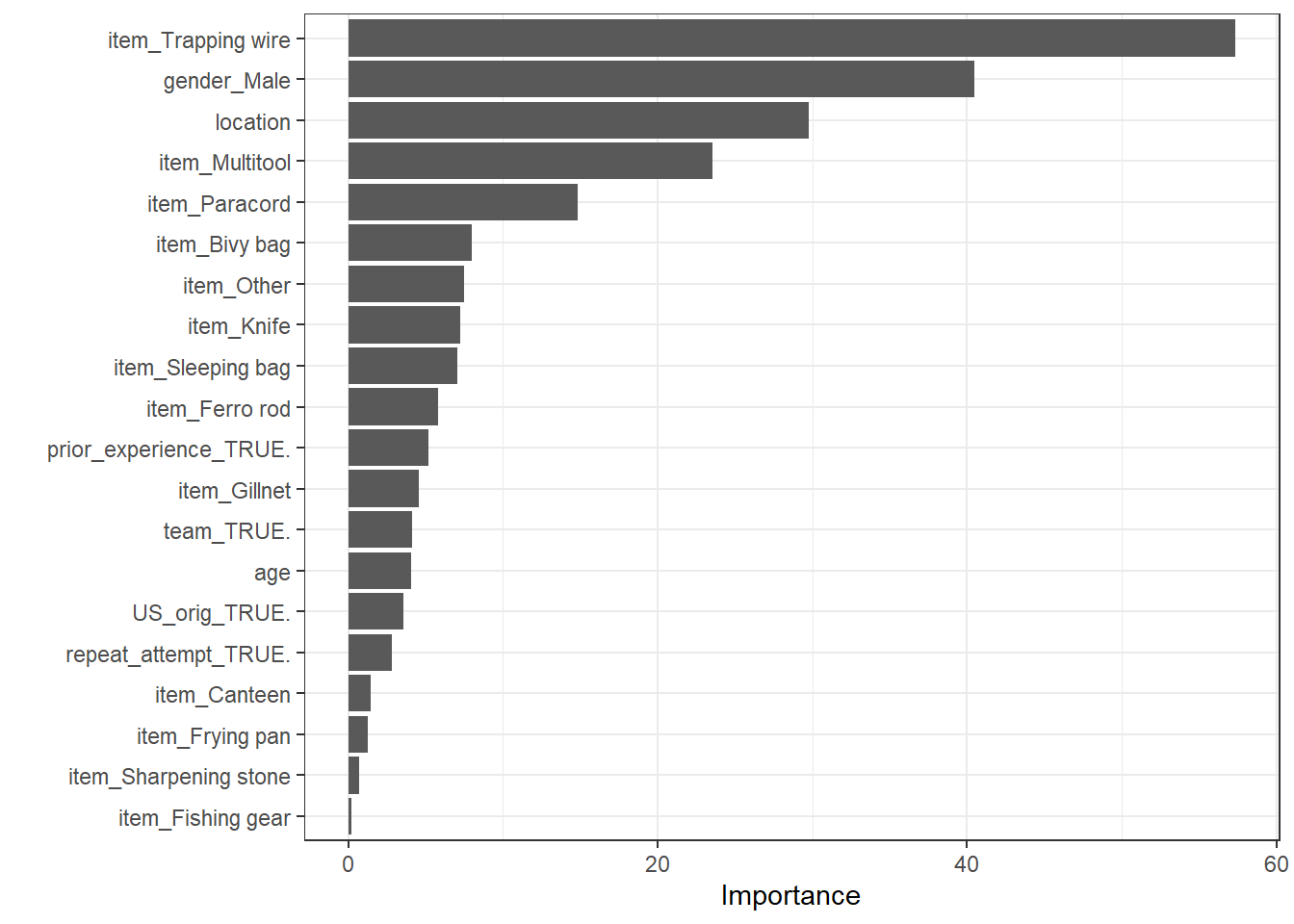
Rows: 94
Columns: 20
$ version <chr> "US", "US", "US", "US", "US", "US", "US", "US", "U…
$ season <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2,…
$ id <chr> "US010", "US009", "US008", "US007", "US006", "US00…
$ name <chr> "Alan Kay", "Sam Larson", "Mitch Mitchell", "Lucas…
$ first_name <chr> "Alan", "Sam", "Mitch", "Lucas", "Dustin", "Brant"…
$ last_name <chr> "Kay", "Larson", "Mitchell", "Miller", "Feher", "M…
$ age <dbl> 40, 22, 34, 32, 37, 44, 46, 24, 41, 31, 50, 44, 45…
$ gender <chr> "Male", "Male", "Male", "Male", "Male", "Male", "M…
$ city <chr> "Blairsville", "Lincoln", "Bellingham", "Quasqueto…
$ state <chr> "Georgia", "Nebraska", "Massachusetts", "Iowa", "P…
$ country <chr> "United States", "United States", "United States",…
$ result <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7…
$ days_lasted <dbl> 56, 55, 43, 39, 8, 6, 4, 4, 1, 0, 66, 64, 59, 57, …
$ medically_evacuated <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, F…
$ reason_tapped_out <chr> NA, "Lost the mind game", "Realized he should actu…
$ reason_category <chr> NA, "Personal", "Personal", "Personal", "Personal"…
$ episode_tapped <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 2, 1, NA, NA, NA, …
$ team <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ day_linked_up <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ profession <chr> "Corrections Officer", "Outdoor Gear Retailer", "B…